InstallPython 3.10+ · install from PyPI, then pull the example dataset
Pull the example dataset (~150 MB from figshare, used by the paper examples and several notebooks):
Opt-in nstat.extras dep groups — install only what you need:
pip install nstat-toolbox[neo,pynapple,nwb] # data-interop bridges
pip install nstat-toolbox[test-parity] # validation oracles (nemos, pykalman, statsmodels)
pip install nstat-toolbox[metrics] # spike-distance metrics (pyspike)
pip install nstat-toolbox[dynamax] # state-space EM (JAX, ~200 MB)
pip install nstat-toolbox[clusterless] # clusterless decoding (JAX, ~200 MB)
pip install nstat-toolbox[all-extras] # all of the above EXCEPT dynamax + clusterless5-minute tourSix runnable snippets covering the most common workflows — each card links to a notebook or paper example
1 Build a spike train core
Wrap a vector of spike times in an nspikeTrain — the universal spike-train object used everywhere in the toolbox.
import numpy as np
from nstat import nspikeTrain
# 100 spikes over 1 second at 1 kHz
times = np.sort(np.random.default_rng(0).uniform(0, 1, 100))
st = nspikeTrain(times, name="neuron1",
sampleRate=1000,
minTime=0.0, maxTime=1.0)
print(f"{st.n_spikes} spikes; rate ~ {st.n_spikes:.0f} Hz")
st.plot()2 Assemble a Trial core
A Trial bundles spike trains, covariates, events, and neighbors for one experiment. The unit that Analysis takes as input.
from nstat import Trial, TrialConfig, Covariate, nstColl
t = np.arange(0, 1.0, 1e-3)
stim = np.sin(2*np.pi*5*t).reshape(-1, 1)
cov = Covariate(t, stim, name="stim",
xlabelval="time", xunitval="s",
ylabelval="vel", yunitval="mm/s",
dataLabels=["stim"])
nstc = nstColl([st])
nstc.setMinTime(0.0); nstc.setMaxTime(1.0)
trial = Trial(nstc, ev=None, covarColl=None, neighbors=None)3 Fit a Poisson GLM + check fit core
Analysis.GLMFit trains a point-process GLM with a stimulus filter and history kernel; FitResult.computeKSStats runs the time-rescaling KS goodness-of-fit test.
from nstat import TrialConfig, ConfigColl, Analysis
cfg = TrialConfig(
covariate_specs=[("Baseline", "constant"),
("stim", "spline")],
sampleRate=1000,
history_window_times=[0.001, 0.002, 0.005, 0.01],
ensCovHist=[],
)
results = Analysis.runAnalysisForAllNeurons(
trial, ConfigColl([cfg]))
fit = results[0][0]
print(f"AIC={fit.AIC:.1f} "
f"KS p={fit.computeKSStats()['ks_pvalue']:.3f}")4 Population goodness-of-fit core
Per-neuron KS plots can pass for every neuron while the model misses inter-neuron coupling. The Tao et al. (2018) marked time-rescaling test catches exactly those failures.
from nstat import population_time_rescale
# counts_list[k] : binned spike counts for neuron k
# lams[k] : model-expected counts per bin
r = population_time_rescale(counts_list, lams,
n_tau_bins=5)
print(f"ground KS p = {r.ground_ks_pvalue:.3g} "
f"mark chi2 p = {r.mark_chi2_pvalue:.3g}")
# On synchronous neurons modeled as independent:
# univariate KS passes; ground KS rejects at ~3e-49.5 State-space EM extras / em
Multi-restart EM with held-out predictive-LL selection — the recommended workflow for PP_EM on real data. Built on Dynamax (JAX) but returns plain NumPy.
from nstat.extras.em.dynamax_bridge import (
fit_point_process_em_best_of)
result = fit_point_process_em_best_of(
spike_counts, state_dim=3,
n_restarts=8, holdout_fraction=0.2)
result.best_result.transition_matrix
result.best_predictive_ll # held-out LL
result.all_predictive_lls # per-seed trace6 Clusterless decoding extras / decoding
Decode position from unsorted multiunit spikes (mark cube of waveform features) plus a discrete trajectory-type classifier on top. Bridges Denovellis 2021's library.
from nstat.extras.decoding.clusterless_bridge import (
fit_clusterless_decoder)
result = fit_clusterless_decoder(
position, # (T, n_position_dims)
multiunits, # (T, n_marks, n_electrodes)
place_bin_size=5.0)
result.posterior # (T, n_position_bins)
result.map_position # (T, n_position_dims)nstat.extrasOpt-in Python-only additions — modeled after scikit-learn-contrib, each subpackage brings its own dep group
The core nstat.* namespace preserves the MATLAB nSTAT
contract (stable, parity-faithful).
nstat.extras.* is the monorepo addon namespace for
Python-only features that have no MATLAB counterpart.
interop data formats
Converters between Trial / SpikeTrainCollection / nspikeTrain and the wider Python neuro stack.
interop.neo— Neo objects ([neo])interop.pynapple— pynapple TS / TSGroup ([pynapple])interop.nwb— NWB units + observation intervals ([nwb])
validation parity oracles
Cross-validation bridges that triangulate nstat's MATLAB-faithful estimates against independent reference implementations.
nemos_bridge— GLM oracle (NeMoS)pykalman_bridge— Kalman / smoother oraclestatsmodels_bridge— Poisson GLM oraclenitime_bridge— spectral analysis cross-check
metrics spike-train distance
Modern multi-neuron spike-train distance metrics via pyspike ([metrics]).
- ISI distance, SPIKE distance, SPIKE-synchronization profiles
em state-space EM
KF_EM / PP_EM / mPPCO_EM equivalents (Dynamax-backed) with the full Tier-0.1 canonical gauge, Tier-0.2 predictive-LL diagnostic, and Tier-0.3 multi-restart selector.
fit_linear_gaussian_em·fit_point_process_em·fit_hybrid_emcmgf_poisson_filter/_smoother(inference on known model)fit_*_em_best_of+point_process_predictive_ll(recommended workflow)
decoding clusterless
Marked point-process state-space decoder + trajectory classifier (Denovellis 2021), the modern descendant of nSTAT's PPAF / PPHF. Spike-waveform features replace spike sorting.
fit_clusterless_decoder(continuous position)fit_clusterless_classifier(replay vs. local etc.)
📚 Visual summary of every nstat.extras bridge — per-card install matrix and runnable code snippets.
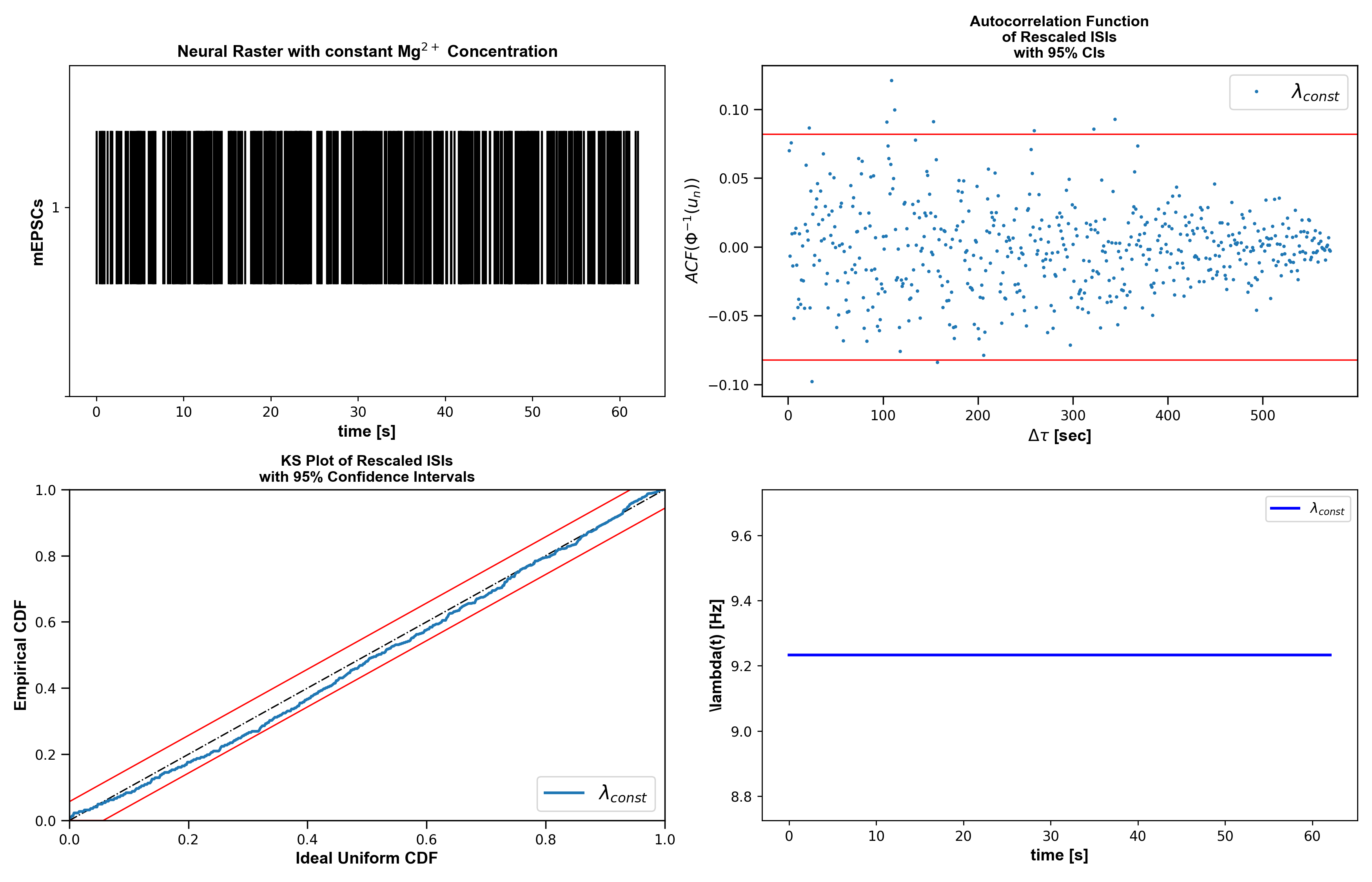
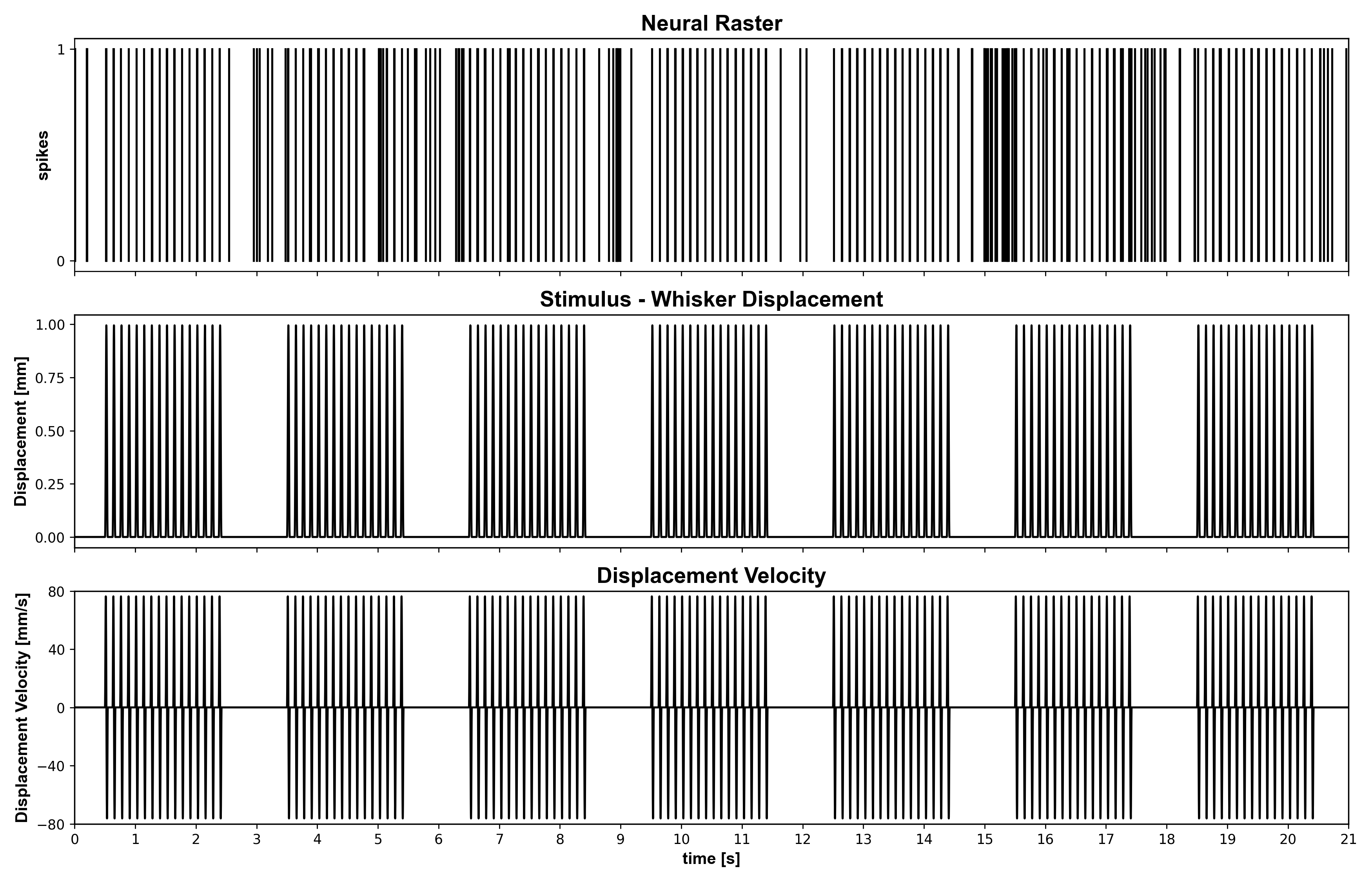
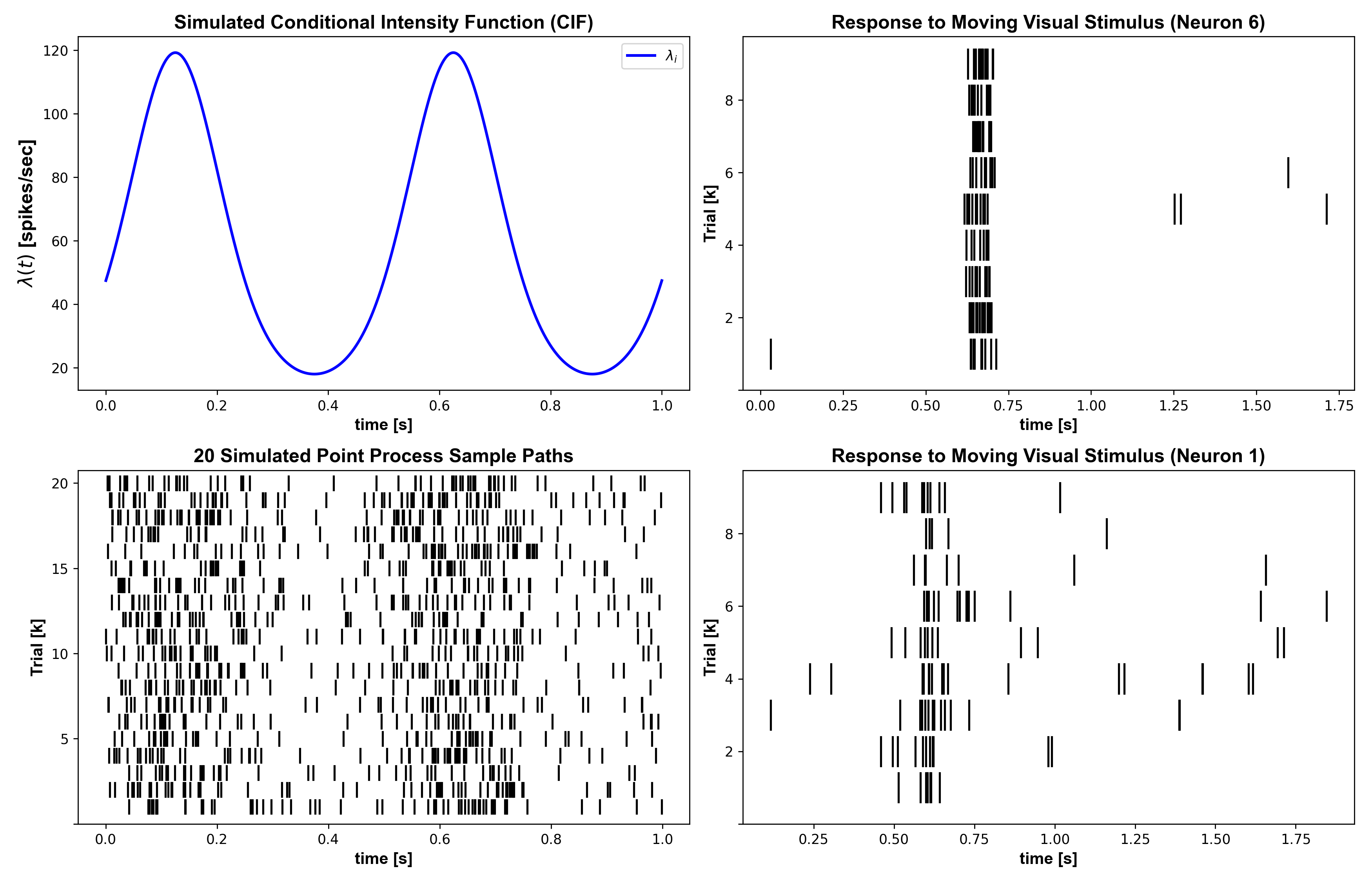
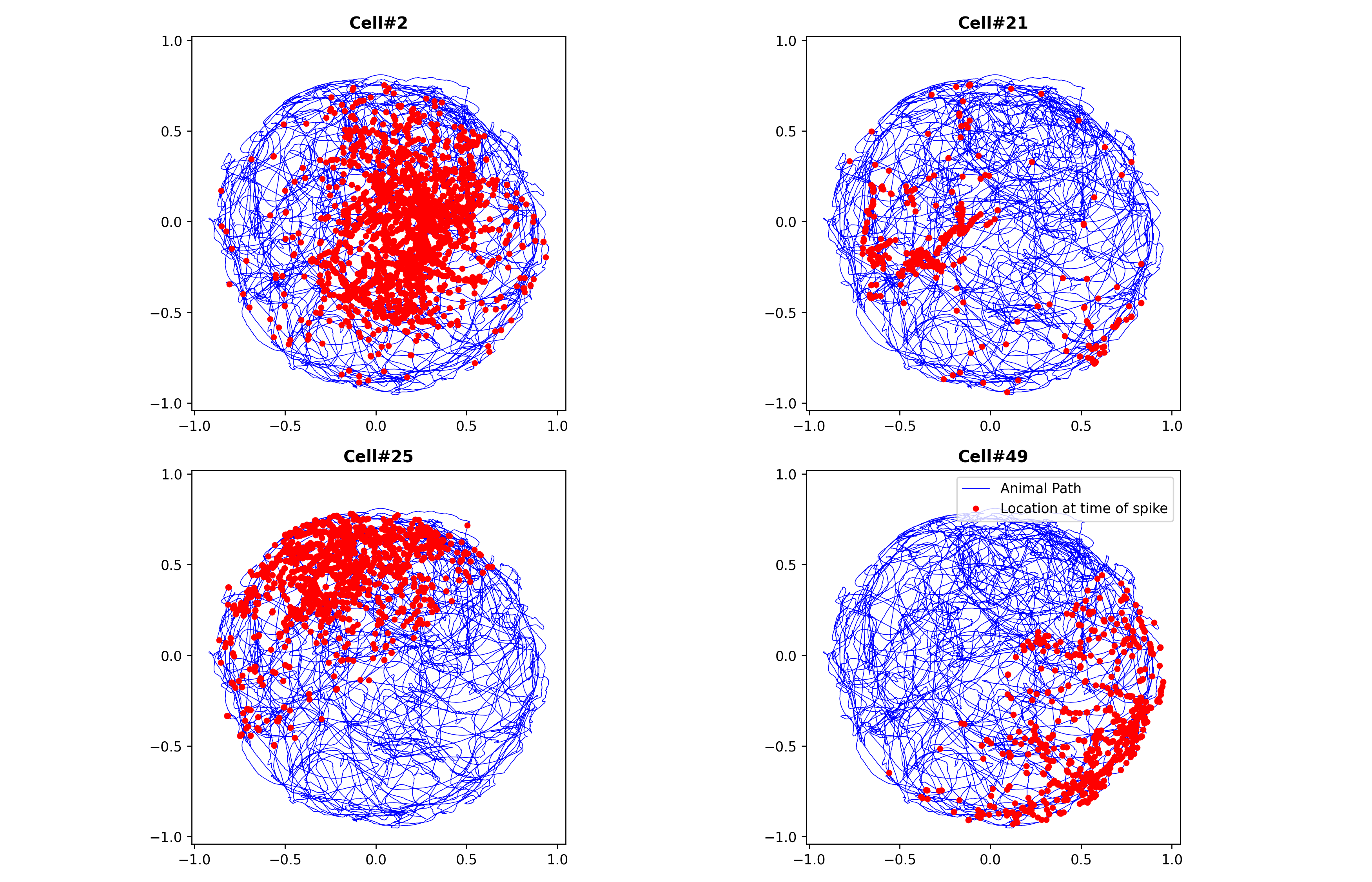
Paper-example galleryThe five canonical paper examples (Cajigas 2012), each runnable in <1 minute on the figshare dataset
Where to nextReference, class maps, release notes, and the road ahead
SignalObj, nspikeTrain, Trial, Analysis, FitResult, …).RELEASE_READINESS.md for the current planning snapshot.notebooks/.